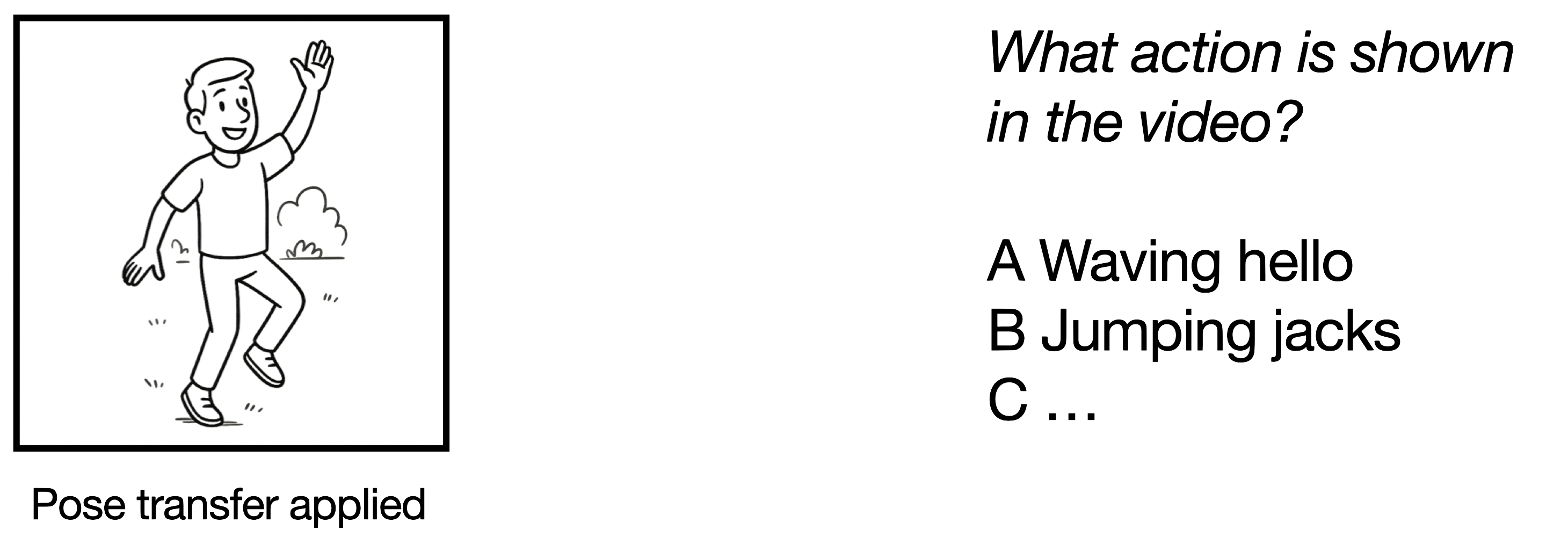Introduction
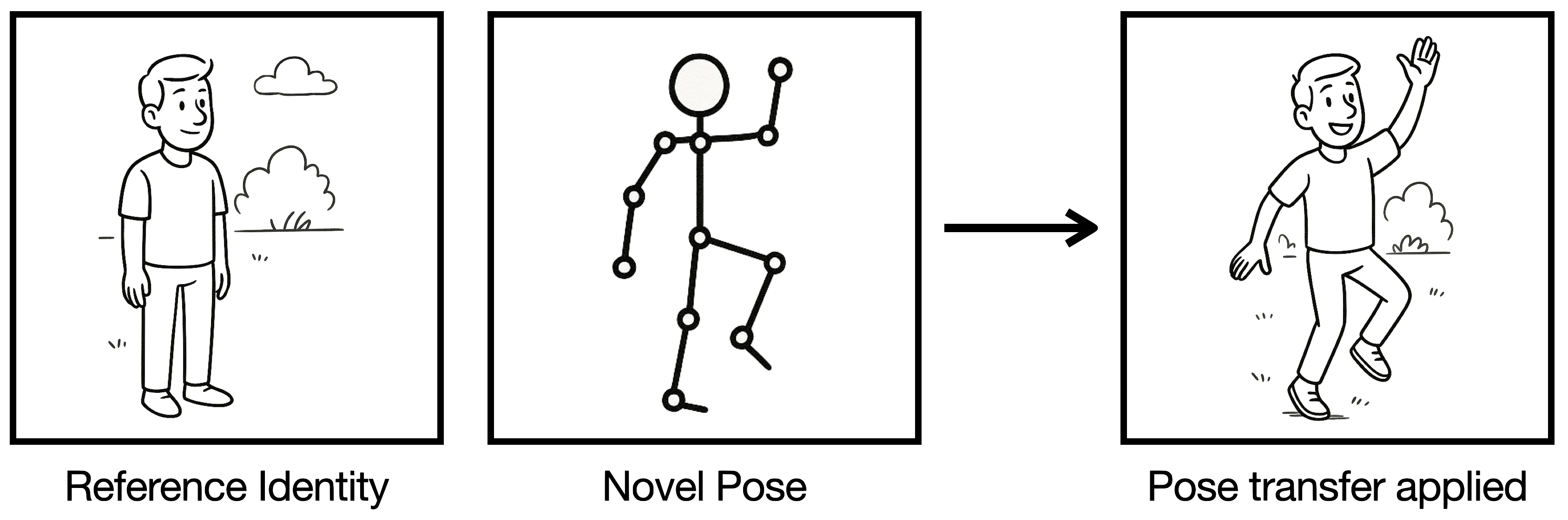
Pose transfer methods generate videos in which a new human identity mimics the actions from a reference video. These techniques have potential applications in areas like animation, healthcare, and fashion, offering new ways to animate humans, assist therapy, or visualize clothing. At their core, pose transfer models work by separating motion from identity and combining them in a believable way.
While state-of-the-art methods such as AnimateAnyone, MagicAnimate, and ExAvatar achieve impressive quantitative benchmark results, their real-world adoption remains limited. This is largely due to the fact that current evaluation relies on quantitative metrics that may not capture how humans actually perceive these generated videos.
To address this gap, we introduce PoseTransfer-HumanEval (PT-HE), a human-centered benchmarking framework. It consists of three complementary participant survey tasks that assess generated videos from distinct angles: (1) whether viewers can recognize the action, (2) whether the motion is consistent with a source video, and (3) how the visuals hold up qualitatively. Each dimension captures an essential part of what makes pose transfer effective in practice.
1/3 Semantics
Can viewers recognize what action is being performed in the generated video? In this task, participants were shown pose-transferred videos and asked to select one of 20 possible action labels from UCF101.
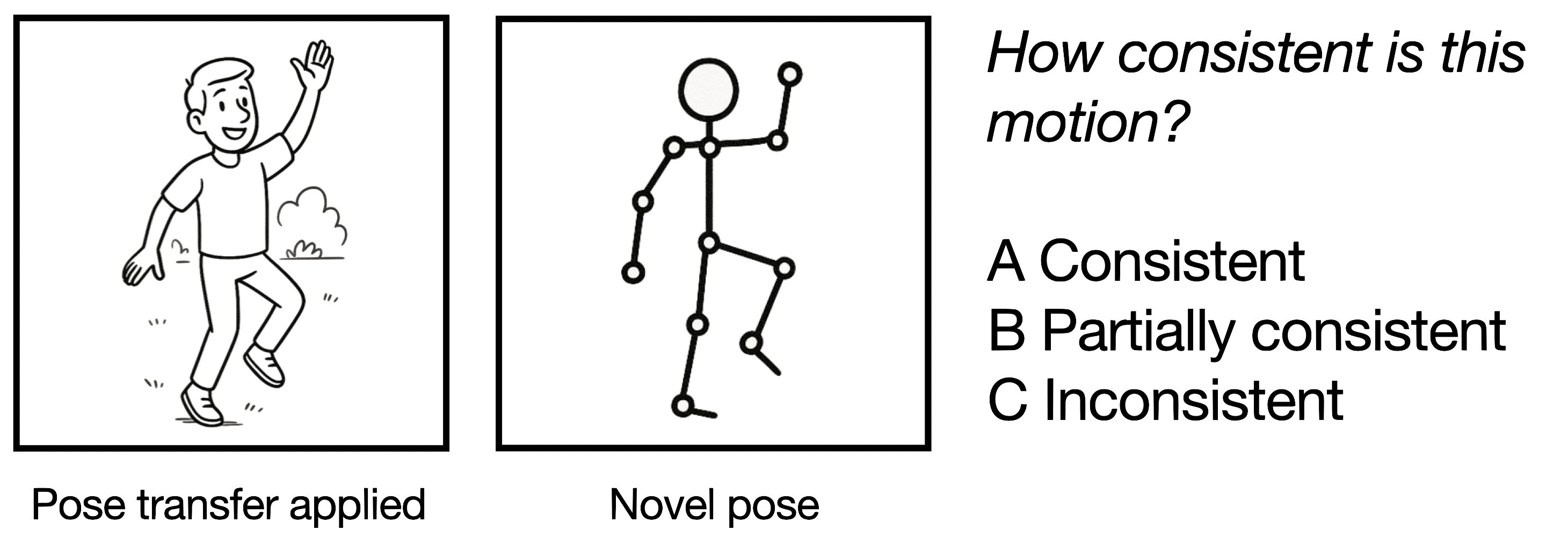
2/3 Consistency
To measure temporal and motion consistency, participants were shown a generated video alongside its source and asked to judge whether the actions match.
3/3 Qualitative
Beyond metrics, we asked participants to describe what they saw—Was the person photorealistic? Was the identity stable? Were there any artifacts?
Demonstration
We demonstrate PT-HE on three prominent pose transfer methods: AnimateAnyone, MagicAnimate, and ExAvatar. In Section 1/3 Semantics, we find that, overall, the majority of videos do not get recognized as the intended action, with ExAvatar outperforming AnimateAnyone and MagicAnimate:
| Method |
Recognition Accuracy (20 cls) |
| AnimateAnyone |
47.50 % |
| MagicAnimate |
13.12 % |
| ExAvatar |
68.12 % |
| Random chance |
5.00 % |
In Section 2/3 Consistency, we find that, while ExAvatar has the highest rate of videos where the action was deemed as consistent among the tested models, approximately 40-45% of videos are deemed as inconsistent across the board:
| Method |
Consistent |
Part. Consistent |
Inconsistent |
| AnimateAnyone |
27.50 % |
25.62 % |
46.88 % |
| MagicAnimate |
26.88 % |
31.25 % |
41.88 % |
| ExAvatar |
55.00 % |
18.12 % |
38.54 % |
Conclusion
Despite strong benchmark performance, current pose transfer models often fail to generate motion that is both semantically clear and visually consistent. Our human evaluation reveals significant gaps between quantitative metrics and real-world perception—especially for out-of-distribution identities and actions—and equips future work in this area with a standardized procedure to conduct human evaluation.
Citation
@article{knapp2025can,
title={Can Pose Transfer Models Generate Realistic Human Motion?},
author={Knapp, Vaclav and Bohacek, Matyas},
journal={arXiv:2501.15648},
year={2025}
}